comment créer un scrapper web avec python en 4 lignes de code
Demandons la solution a chatgpt. Ecris en python, chatptg est tout a fait capable de générer automatiquement du code python sur demande.
nous devons installer la librairie python beautifulSoup 4, c'est un analyser html xml qui permet de decomposer une page web, du css et meme d'extraire les fichiers javasrcript
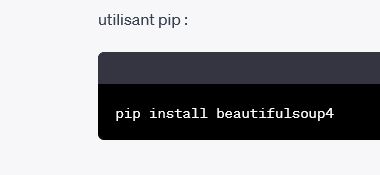
Le code généré par chatgpt est effectivement écrit en 4 lignes de code avec Python.
Si on pouvait effectivement supposer que c'était faisable, sinon on ne l'aurait pas demander à chagpt,
on peut penser que peu de personnes on posé cette question auparavant et la performance de chatpt nous laisse sans voie
Quel intérête pour le SEO ?
Nous allons pouvoir trouver comment le bot de google voit nos sites (c'est parfois très révélateur), et surtout faire tout ce qu'on peut faire avec des sources web, automatisés.
Ce sont certes juste 4 lignes de codes qui montrent qu'on peut ramener un contenu d'une page web, n'inporte quel browser le fait.
Il suffit de faire view source sur une page web pour voir le code soirce d'une page web.
Oui mais cette fois le contenu de la page est demandé par un programme écrit en python, analysé automatiquepent par un programme aussi écrit en python.
Résultat, on récupère les données du site web dans une structure python, et le champ d'utilisation de ces données est immense, il va de google a chatgpt, à notre >propres programmes d'analyses SEO
et on ne pert pas de temps a afficher le rendu d'un site web, donc, on peut scrapper des sites très vites, pour analyser leur contenu, sans gener leur comportement.
Ces 4 lignes de codes sont donc la première pierre de vos outils potentiels en python pour analyser une page web, 'tranquillement'.
Regardons le code généré en pyton pour scrapper une page - technique SEO
- l'objet python , qui permet de lire une page s'appelles requests. En utilisation standard, il est extremement simple a utiliser. il suffit de lui donner une url en paramètre
Dans l'example ci-dessus, il reçoit en paramètre la variable url, définit la ligne au dessus par la valeur "https://example.com".
Le résulat de la requete/méthode de l'objet requsets (le contenu de la page web) est placé dans une structure nommée "response".
Sur le même principe, on donne notre contenu a un objet beautifulSoup, en présiant danses paramêtres qu il doit travailler avec un analyseur de code de type html.
beautifulSoup, nous retourne une'soupe' de code html, avec laquelle on peut tout faire.
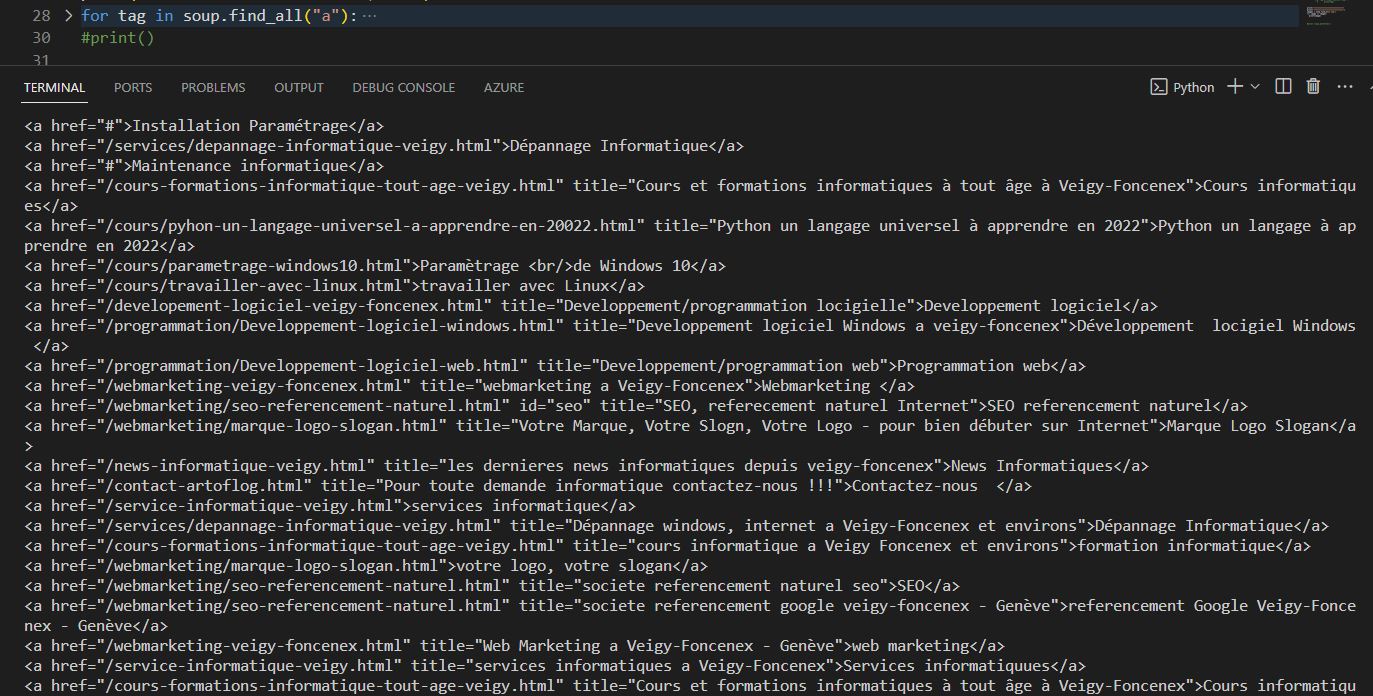
Afficher les liens a d'une page web
for tag in soup.find_all("a"):
print(tag)
Un premier outil, se présenter "as google"
Le bot de Google se présente au serveur web avec une signature particuliere dans son header
Sa signatuure est officielle, on peut la trouver a l'adresse : https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers?hl=fr
Imiter sa signature consiste donc simplement a modifier le useragent de notre query. Et la aussi python nous simpifie la tache.
Il suffit de rajouter le paramêtre header dans la fonction get de l'objet requests

Si par malheur on tombait sur un site qui ne retournerait pas le même contenu que quand on se présente comme un utilisateur normal, cela signifieraut que le site utilise une vieille technique SO, totalement proscrite par google aujourd'hui.
il fut une époque, ou des sites qui revendaient des milliers de backlink, ne prposaient pas du tout ce contenu à googe, un véritable annuaire de liens sans le moindre intérêt du point de vu du contenu.
Mais c'est dans le sens inverse quils repéraient les bots de google et qu'ils leur retournaient un bon site web optimisé, pour les mots clés de l'annuaire.
Aujourd'hui google repere ces sites et les met a la poubelle dans son index.
Parfois ils sont redéveloppés encore et revivent le temps d'une mise à mort par google, qui n'est pas effective rapidement
pour commencer a développer avec python de a a Z, il faut traiter en tout premier le sujet des :variables python, et déjà python se montreun langage très particulier dans
le sujet des: variables python : --> Les variables en python